К 2025 году ИИ отберёт работу у 85 млн человек. Но в то же время создаст огромное количество новых рабочих мест и возможностей для бизнеса. В каком лагере окажемся мы? Чтобы выиграть от расцвета ИИ, нужно уже сейчас понимать его возможности, а ещё лучше применять в своих проектах. Поэтому сегодня в мини-курсе мы подготовили обзор основных возможностей ИИ для бизнеса. 10 шагов:1. Генерируем тексты с помощью GPT-32. Создаём изображения: DALL-E 23. Генерируем код: OpenAI Codex4. Используем компьютерное зрение для автоматизации процессов 5. Создаём дипфейк-видео 6. Редактируем изображения с помощью нейросетей 7. Переводим аудио в текст 8. Копируем голос другого человека и исправляем акцент 9. Находим инсайты в массивах информации 10. Внедряем модели в бизнес: инструменты MLOps | |
| | 1. Генерируем тексты с помощью GPT-3 | |
| GPT-3 — самый мощный и перспективный алгоритм генерации текстов на сегодня. Он уже умеет сочинять стихи, анализировать большие массивы текста, вести диалоги и отвечать на вопросы. Вот примеры коммерческих применений GPT-3: Ещё 300+ сервисов с разбивкой по категориям можно посмотреть на GPT-3 Map. В скором времени ожидается релиз GPT-4 — эта модель будет содержать уже 100 трлн параметров, что в 500 раз больше GPT-3. А значит, генерация текстов будет ещё более качественной. Как это применить? API в открытом доступе без листа ожидания. Однако для коммерческих проектов нужен счет в другой стране — РФ, Беларусь и Украина не поддерживаются. В Сбере разработали русскоязычную модель ruGPT-3, есть API и готовые модели на GitHub. Также недавно в открытый доступ выложили языковые модели от Meta (экстремистская организация) и Яндекса. | |
| | 2. Создаём изображения: DALL-E 2 | |
| Технология генерации изображений из текста также совершила мощный рывок за последний год. Нейронки уже могут конкурировать с художниками и иллюстраторами — и не только с любителями. Они умеют генерировать картинки с нуля по текстовому описанию, дорисовывать часть картинки, изменять заданное изображение. Примеры картинок можно посмотреть здесь. Вот основные проекты для генерации изображений: - DALL-E 2 — нейросеть от OpenAI, создателей GPT-3. Модель умеет добавлять/удалять объекты на изображении и создавать вариации заданных картинок. Пока только лист ожидания, но некоторым уже начали выдавать доступы. Есть и копии архитектуры на GitHub. В Сбере также адаптировали модель под русский язык и выложили на GitHub.
- Latent Diffusion — ещё одна модель, которая умеет генерировать и редактировать картинки по текстовому описанию. Код открыт, также можно поиграться в песочнице.
- GLIDE — диффузионная модель от OpenAI. В ней можно настроить баланс между скоростью генерации и качеством результата. Код открыт.
Со всеми доступными генераторами изображений можно поиграться в этой демке на Huggingface. | |
| | 3. Генерируем код: OpenAI Codex | |
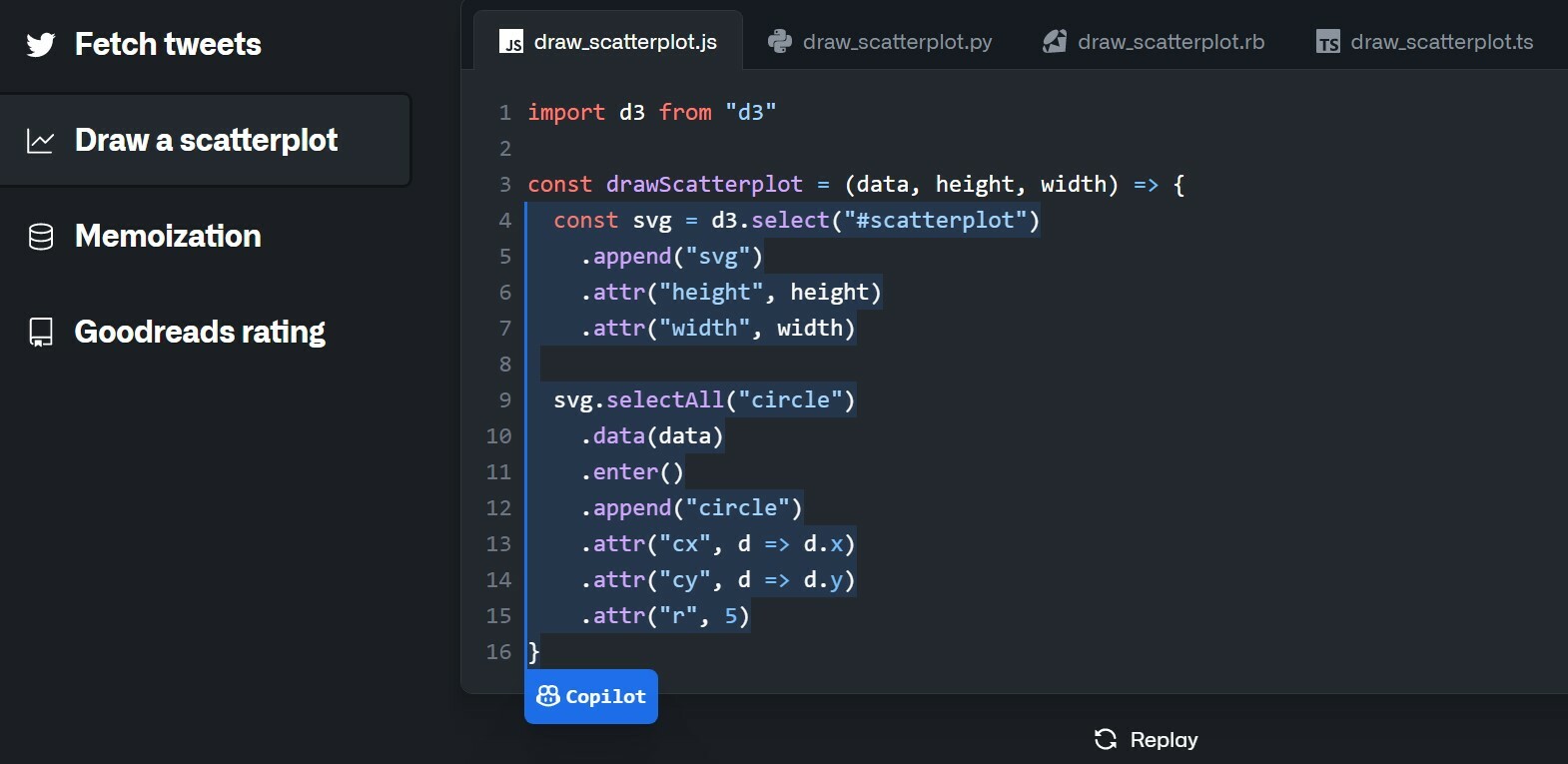
| Программисты тоже на прицеле у ИИ. Нейронки и здесь совершили скачок, обучившись на открытых репозиториях кода: - OpenAI создали Codex — это модифицированная версия GPT-3, которая трансформирует обычный язык в код. На базе Codex уже есть ИИ-помощники для программистов, которые дополняют код (GitHub Copilot). Можно также генерировать программы из дизайнов Figma, объяснить написанный код человеческим языком, автоматически создавать юнит-тесты.
- Salesforce выложили в открытый доступ CodeGen — модель, которая превращает инструкции на обычном языке в код. Пишут, что их модель может конкурировать с Codex.
- Amazon на днях выпустили CodeWhisperer — собственного ИИ-помощника для программистов, который подстраивается под стиль разработчика и может генерировать более 10 строчек кода за раз.
- Kite, Tabnine — ИИ-плагины, которые предсказывают следующие строчки кода.
Как это применить? Генерировать код можно с помощью API Codex (модель code-davinci, пока что в листе ожидания). Нейросетке можно давать задание на обычном английском, и перебирать варианты. Пример из недавнего: Codex сама написала аналог Wordle, Zelda и 3D-лабиринт — и всё это без кода от человека. | |
| Продолжение, шаги 4-10 доступны в сообществе Unity4. Используем компьютерное зрение для автоматизации процессов 5. Создаём дипфейк-видео 6. Редактируем изображения с помощью нейросетей 7. Переводим аудио в текст 8. Копируем голос другого человека и исправляем акцент 9. Находим инсайты в массивах информации 10. Внедряем модели в бизнес: инструменты MLOps | |
| | Годное чтиво за эту неделю | |
| | Так выглядит описание многих вакансий:
«Нам в компанию нужна девственница, с опытом в сексе не менее 2-х лет». | |
| |